Your AI, on your device.
No cloud. No compromise.
Privami AI runs large language models entirely on your Android phone. Web search, a configurable system prompt, and full parameter control — all without sending a single message to an external server.
Features
Everything you need.
Nothing you don't.
100% local inference
The model runs entirely on your phone. Your prompts, your conversations, and your data never leave the device.
Web search via DuckDuckGo
Toggle web search on before sending a message to let the model pull real-time results — no API key needed, no tracking.
Configurable parameters
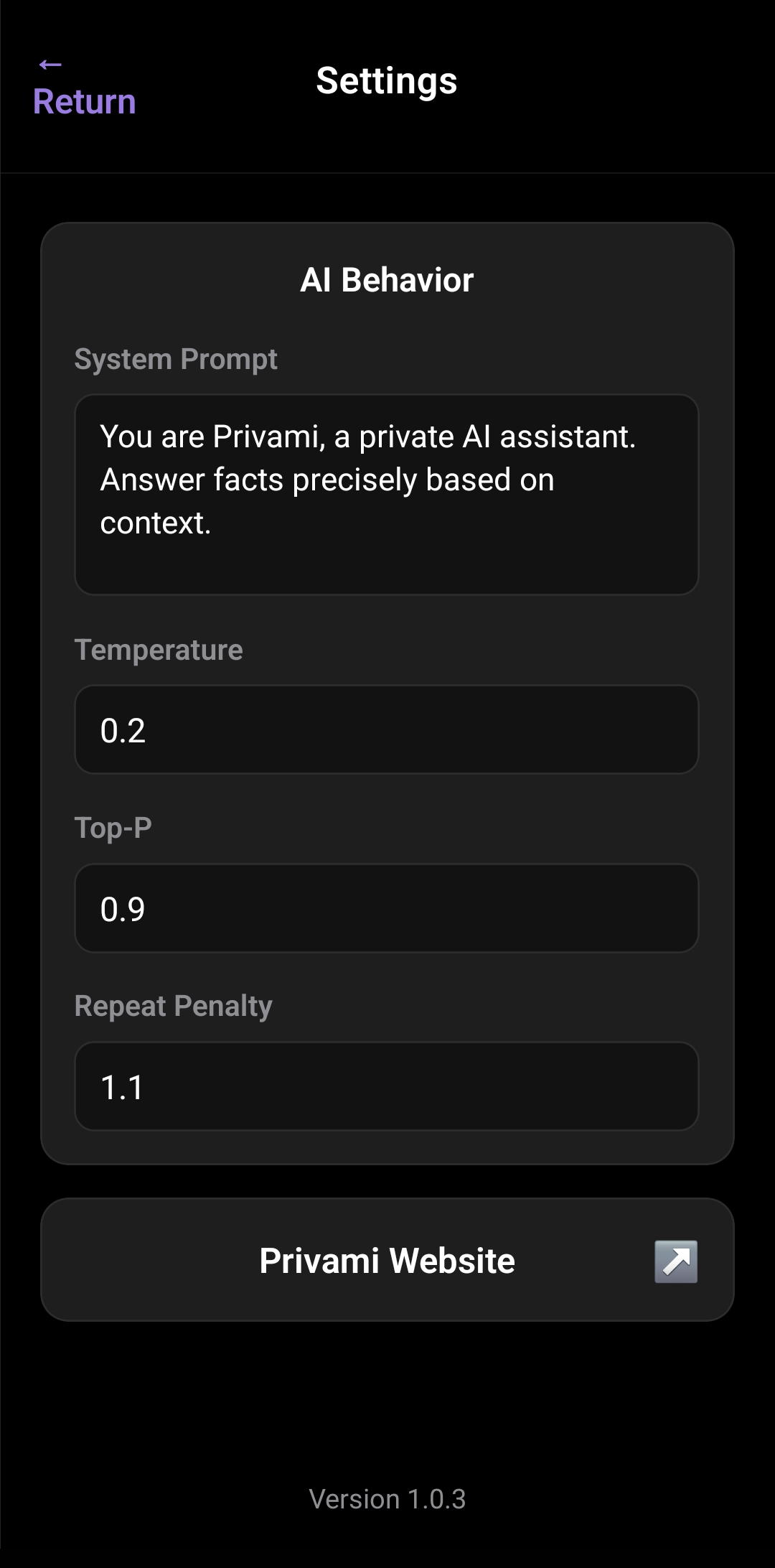
Adjust temperature, top-p, top-k, repeat penalty and more directly in the app. Tune the model's behavior to exactly what you need.
Custom system prompt
Define the model's persona, tone, and behavior before any conversation starts. Make it a tutor, an assistant, a creative partner — your call.
Curated model selection
Ships with four hand-picked models ready to download directly in the app — Llama 3.2 1B, Qwen2.5 0.5B, DeepSeek-R1-Distill-Qwen-1.5B, and SmolLM2-1.7B.
Open source
Everything is open on GitHub. Fork it, inspect it, build on it. Based on EdgeLLM by MekkCyber.
Screenshots
See it in action


Web search
Real-time results, one tap away.
Tap the web search button
Before writing your message, tap the web search toggle in the chat input bar. The button lights up to show it's active for this prompt.
Send your message
Type and send your question as usual. The app detects that web search is on and fires a query to DuckDuckGo — no API key required, no account needed.
Results are injected as context
The top results from DuckDuckGo are passed silently to the model as additional context, giving it access to information it wouldn't otherwise have.
The model answers with fresh data
The local model generates a response grounded in both its training and the live search results. You stay in control — search only runs when you explicitly enable it.
Configuration
Fine-tune everything.
| Parameter | What it does |
|---|---|
| temperature | Controls how creative or predictable the model's answers are. Lower values produce more focused, deterministic responses; higher values produce more varied and exploratory ones. |
| top_p | Nucleus sampling — the model considers only the set of tokens whose cumulative probability reaches this threshold. Lower values make the model more conservative. |
| repeat_penalty | Discourages the model from repeating the same words or phrases. Raise it if responses start looping; lower it for creative writing where repetition might be intentional. |
| system_prompt | A freeform instruction that defines the model's persona and behavior before any conversation starts. Use it to set the tone, role, language, or constraints for the assistant. |
Supported models
Download models directly in the app.
Privami AI comes with built-in support for the following models — no manual downloads or file management needed. Just open the app and download the one you want to use.